ABC207C Many Segments
ABC207C Many Segments 题解
题面
题目描述
给定 $N$ 个编号为 $1$ 到 $N$ 的区间。第 $i$ 个区间的定义如下:
- 如果 $t_i=1$,则区间为 $[l_i, r_i]$;
- 如果 $t_i=2$,则区间为 $[l_i, r_i)$;
- 如果 $t_i=3$,则区间为 $(l_i, r_i]$;
- 如果 $t_i=4$,则区间为 $(l_i, r_i)$。
请问满足 $1 \leq i < j \leq N$ 的整数对 $(i, j)$ 中,有多少对区间 $i$ 和区间 $j$ 存在公共部分?
区间 $[X,Y]$、$[X,Y)$、$(X,Y]$、$(X,Y)$ 的定义如下:
- 闭区间 $[X,Y]$ 表示所有大于等于 $X$ 且小于等于 $Y$ 的实数的集合;
- 半开区间 $[X,Y)$ 表示所有大于等于 $X$ 且小于 $Y$ 的实数的集合;
- 半开区间 $(X,Y]$ 表示所有大于 $X$ 且小于等于 $Y$ 的实数的集合;
- 开区间 $(X,Y)$ 表示所有大于 $X$ 且小于 $Y$ 的实数的集合。
简而言之,方括号 $[]$ 表示包含端点,圆括号 $()$ 表示不包含端点。
输入格式
输入以如下格式从标准输入读入:
$N$
$t_1$ $l_1$ $r_1$
$t_2$ $l_2$ $r_2$
$\vdots$
$t_N$ $l_N$ $r_N$输出格式
输出区间 $i$ 和区间 $j$ 存在公共部分的整数对 $(i, j)$ 的个数。
限制条件
- $2 \leq N \leq 2000$
- $1 \leq t_i \leq 4$
- $1 \leq l_i < r_i \leq 10^9$
- 输入均为整数
题解
本题考验的主要是C++不同的算法设计思路——加粗样式加倍法处理整数间数据包含误差、通过边界处理统一数据形式。
边界处理
本题比较复杂的是四种不同的边界表达方式的处理与判断。那么,如何把他们统一为同一种范围表示形式,从而方便后续的统一处理分析呢?
通过简单的处理和思考,我们可以把四种区间表达形式归类为同一种区间表达。 最初的边界处理方法应该是这样的:(本题解的方法统一将所有区间通过闭区间表示) 对于一端的开区间(如$(l,r]$),我们只需要尝试将左侧开区间转换为闭区间即可。目前易得$l < x$可以转换为$l + 1 \le x$。
但是,这真的完全正确吗?
加倍法
在边界处理的条件下,让我们来思考一个问题。
假设两个区间$[2,3)$$(2,4]$,这两个区间理应有重合部分(比如$2.5$,这里要注意虽然输入是整数,但是在数轴上包含关系可以算上包含小数);但是使用我们的转换方法,这两个区间会归类为$[2,2]$和$[3,4]$,此时两个区间明显无交集,这显露出了一个大问题:我们在边界处理时没有考虑整数之间小数的留存,导致极端数据下有答案遗漏。
解决这个问题的关键点在于我们只需要精准地统计包含区间对的个数。我们所产生的问题不是在归类时不考虑部分小数,而是丢弃小数影响结果。 所以,我们不妨在输入数轴的每个整数点$i$和$i + 1$间分别插入一个点,代表$i$和$i + 1$间的所有小数,即加倍数组长度,这样就可以在加倍后的数组中$l++,r–$从而只影响整数单个点的包含结果而不影响小数部分的包含结果。
那么,此时在输入环节中的区间预处理代码已经明确:
1
2
3
4
5
6
7
8
9
10
11
for (int i = 1;i <= n;i++) {
int t,l,r;
cin >> t >> l >> r;
l *= 2,r *= 2;
switch(t) {
case 1: {a[i] = {l,r}; continue; }
case 2: {a[i] = {l,r - 1}; continue; }
case 3: {a[i] = {l + 1,r}; continue; }
case 4: {a[i] = {l + 1,r - 1}; continue; }
}
}
区间相交判断
区间$A,B$相交有两种情况:$A$在$B$前或$B$在$A$前。
我们可以通过画图理解两种情况: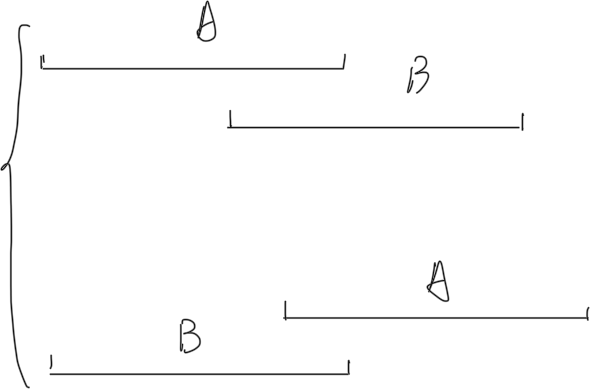
这里要注意因为两个区间都是开区间,所以我们使用$\le$或$\ge$进行判断,易得判断条件是$A.r \ge B.l,A.l \le B.r$,因为数据范围中$N \le 2000$,所以支持暴力枚举$A$和$B$:
1
2
3
for (int i = 1;i <= n;i++)
for (int j = i + 1;j <= n;j++)
if (a[i].first <= a[j].second && a[j].first <= a[i].second) ans++;
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
#include<iostream>
using namespace std;
const int N = 2e4 + 5;
pair<int,int> a[N];
int main() {
int n,ans = 0;
cin >> n;
for (int i = 1;i <= n;i++) {
int t,l,r;
cin >> t >> l >> r;
l *= 2,r *= 2;
switch(t) {
case 1: {a[i] = {l,r}; continue; }
case 2: {a[i] = {l,r - 1}; continue; }
case 3: {a[i] = {l + 1,r}; continue; }
case 4: {a[i] = {l + 1,r - 1}; continue; }
}
}
for (int i = 1;i <= n;i++)
for (int j = i + 1;j <= n;j++)
if (a[i].first <= a[j].second && a[j].first <= a[i].second) ans++;
cout << ans << endl;
return 0;
}